* (참고) 추후에 내가 보았을 때 어떤 내용의 논문인지 기억할 수 있을 정도로만 간단히 정리하는 리뷰임.
매우 러프함 주의
LVLM
: 비전 이미지를 input으로 넣었을 때, caption, report를 생성
Medvill은 처음으로 메디컬 이미지에 대한 LVLM 모델을 제안
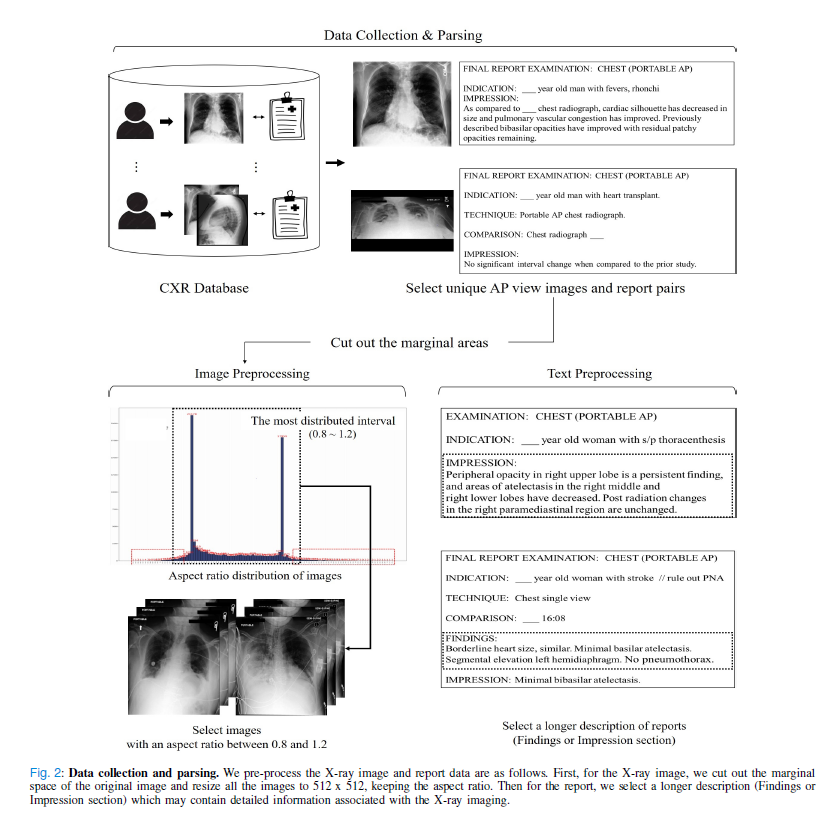
데이터 전처리는 이미지에 대해서 가낭 높은 distribution 값 사이의 이미지를 사용. (0.8~1.2 사이)
이는 데이터 불균형 및 오버피팅을 막기 위함.
text에 대해서는 긴 description을 가진 text들만 골라서 사용. 더 자세한 설명을 학습에 사용하기 위함.
해당 논문에서 제안하고자 하는 것은 visual (이미지) embedding과 Language (description) embedding을 진행하고 이를 joint해서 서로 간의 관계성 파악 후 이미지가 input으로 들어오면 그에 맞는 description을 뱉어내겠다는 것!

1) Visual Feature Embedding
CNN을 사용해서 마지막 단에서 추출된 이미지의 특징들을 사용.
또한, 랜덤 마스킹을 통해 오버피팅을 막고 전체적인 이미지를 잘 학습할 수 있도록 함
2) Language Feature Embedding
BERT 를 사용함.
토큰으로 나누어서 feature extraction. 여기서도 당근 어떤 문장 내의 단어를 마스킹하고 어떤 단어가 올지 예측하도록 함.
3) Joint Embedding
이렇게 얻은 두가지 데이터를 joint함. MedVill의 아래쪽에 있는 것이 visual embedding으로 얻어낸 이미지의 class token과 seperate token이다.
* 기존 bert처럼 SEP은 문장과 그림을 나누어주는 용도, CLS는 스페셜한 정보들을 가지고 있는 토큰.
이후에는 self attention으로 관계성 학습.
이 때는 어떤 task인지에 따라 다르게 학습함
