[LLM] Llama3 api 실습해보기 with Hugging Face 🤗
LLM 공부 시작 ......
LLM을 활용한 데이터베이스 튜닝 논문이 탑티어 학회에 나오고있는걸 보니.. 나도 LLM을 찍먹이라도 해봐야겠다 싶어 시작..
Llama가 그나마 실습해보기 간단하고 쉬워보여서 고고싱 (하지만 쉽지않았다)
진짜 기초부터 차례대로 정리했음
먼저, hugging face의 transformers를 설치해줘야하는데 그 전에 가상환경을 만들고 그 안에서 설치해야함
그래서 일단 conda 가상환경 만드는 것부터 설명하자면..
정말 간단하다.
anaconda 설치
https://www.anaconda.com/download/success
Download Now | Anaconda
Anaconda is the birthplace of Python data science. We are a movement of data scientists, data-driven enterprises, and open source communities.
www.anaconda.com
여기 사이트에 가서 현재 내 os에 맞는 배쉬 파일을 다운받고 내 서버에 파일을 갖다놓으면 된다.
그 다음엔 배쉬 파일을 실행시켜주믄 됨,,
~$ sh Anaconda3-2024.10-1-Linux-x86_64.sh
실행시키면 와르르르 약관이 쭈욱 나오는데 그냥 Alt+F 누면 맨 밑으로 넘어간다.
거기서 동의하냐 안하냐 Yes/No 입력하라고 하는데 Yes 치고 엔터 누르면 된다 ㅎㅎ
설치 위치도 알려주면서 여기에 해도 되니? 하는데 ㅇㅇ그냥 된다하고 엔터 쭉쭉 누르면 됨,,
만약에 설치 경로 바꾸고 싶으면 바꿔줄 수 있다.
그럼 설치 완료,,,,
anaconda env 만들기
이제 가상환경을 만들어줘야한다
이것도 매우매우 간단하다
~$ conda create -n {env_name} python={version}
이렇게하면 지정한 이름을 가진 가상환경이 만들어진다.
가상환경을 active하고싶을 땐
conda activate {env_name} 하면 된다!
필요한 도구들이랑 버전들은 아래 적어두었음!
맞춰서 다운받으면 된다.
Hugging Face API 키 발급
Hugging Face – The AI community building the future.
The Home of Machine Learning Create, discover and collaborate on ML better. We provide paid Compute and Enterprise solutions. We are building the foundation of ML tooling with the community.
huggingface.co
허깅페이스 홈페이지에 가서 먼저 회원가입을 한다.
프로필누르고 Settings - Access Tokens 가서 토큰 발급받기
이제 반 왔다!
Llama 실습
https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct
meta-llama/Meta-Llama-3-8B-Instruct · Hugging Face
The information you provide will be collected, stored, processed and shared in accordance with the Meta Privacy Policy. META LLAMA 3 COMMUNITY LICENSE AGREEMENT Meta Llama 3 Version Release Date: April 18, 2024 "Agreement" means the terms and conditions fo
huggingface.co
실습하고싶은 모델 찾아서 모델에 대한 권한받기
나는 인기 많아보이는 걸로 선택했다.
참고로 권한신청한다고 바로 사용이 가능한건 아님!!
access granted 됐다고 메일이 날라온당
이 이메일은 받았으면 사용 가능한 상태가 됨!
자 그 다음에는 vscode에 가서 주피터노트북 파일을 하나 만든다
근데 진짜 중요한 부분이 있다.. 언제나 늘 중요한 버전..버전 맞추기..
transformers==4.31.0 # For working with Meta LLaMA and BitsAndBytesConfig
accelerate==0.21.0 # For multi-GPU handling and model acceleration
bitsandbytes==0.38.1 # For 8-bit quantization
scipy==1.9.3
+) 가상환경 만들 때 python 3.9이상으로
이 버전으로 맞추면 위에 올려둔 모델에 대해서는 버전이 잘 맞는다....
땡스 투.. ↓
https://huggingface.co/stabilityai/StableBeluga2/discussions/23
stabilityai/StableBeluga2 · RuntimeError: shape '[1, 60, 64, 128]' is invalid for input of size 61440
huggingface.co
그리고 다음과 같이 코드 작성
import os
os.environ['HF_TOKEN']="Personal Token"from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "meta-llama/Meta-Llama-3-8B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16,
device_map="auto",
)def generate_response(system_message, user_message):
combined_message = f"{system_message}\n\n{user_message}"
# 입력 메시지를 토큰화
input_ids = tokenizer(
combined_message,
return_tensors="pt"
).input_ids.to(model.device)
# 종료 토큰 설정
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>") if "<|eot_id|>" in tokenizer.get_vocab() else tokenizer.eos_token_id
]
outputs = model.generate(
input_ids,
max_new_tokens=512,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9
)
# 응답 부분만 잘라서 디코딩
response = outputs[0][input_ids.shape[-1]:]
return tokenizer.decode(response, skip_special_tokens=True)response를 받기 위한 함수
system_message = "You are a database administrator."
user_message = "What is the top 10 important parameters in mysql?"
response = generate_response(system_message, user_message)
print("DBA Response:", response)이렇게 예를 들어서 "넌 DBA야. mysql에서 중요한 10개의 파라미터는 어떤게 있어?"
라고 물어보면
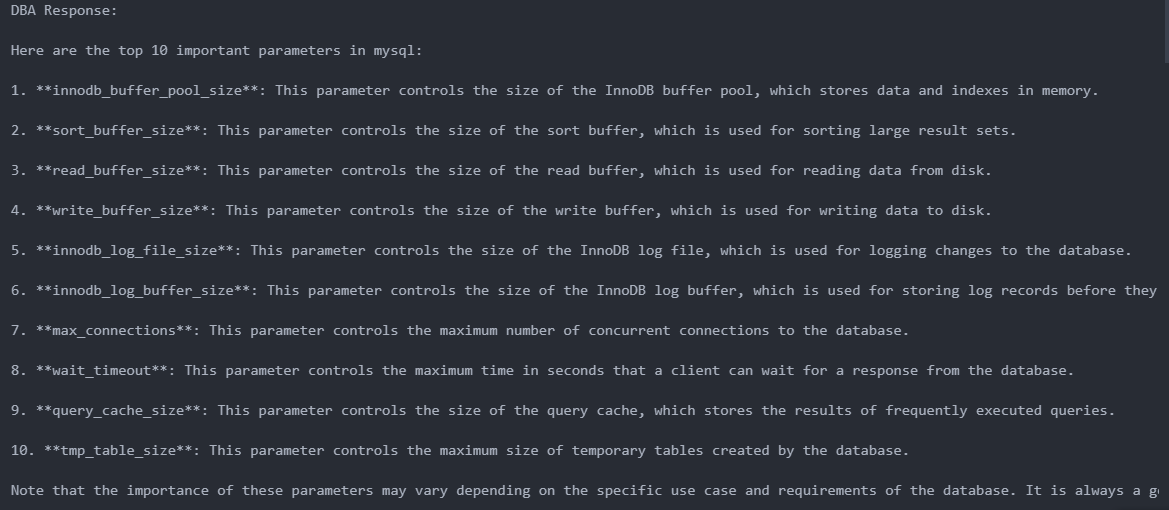
이런식으로.. 대답을 아주 잘해준다!!!!
